Docker - How it Works
Docker is a platform that enables the packaging of software inside encapsulated userland runtime environments called containers1.
Containers
Containers leverage a number of Linux kernel features - the most notable being namespaces and control groups (cgroups).
Linux namespaces partition system resources such that any given process sees only the resources within its own namespace.
There are different types of namespaces depending on the resource. Let’s take a look at some of the types leveraged by containers:
User namespaces
User namespaces provide privilege isolation and segregation for a set of running processes, without those processes being aware.
Each process is a member of exactly one user namespace and is assigned a pair of user/group IDs inside of that user namespace. Outside of that user namespace, the process can have an entirely different pair of user/group IDs2.
In other words, a process can have one set of privileges inside of its user namespace, and another set of privileges outside of it.
In the context of containers, this means processes can run as root from the container’s perspective and as an unprivileged user from the host system’s perspective.
This is a very powerful security feature. By packaging up our applications inside of containers, we can limit their access to the host system’s resources - making the host less vulnerable to attacks if our application were to become compromised.
UTS namespaces
Unix Time Sharing (UTS) namespaces provide hostname isolation. Processes running in one UTS namespace can have a separate hostname from those running in another UTS namespace.
In other words, a container can have a separate hostname from that of the host system and other containers.
PID namespaces
Process ID (PID) namespaces isolate the PID number space, allowing processes in different PID namespaces to have the same PID.
This means we can have multiple containers on the same host each running a process with PID 1 from their own perspective3. From the host’s perspective, these processes are still mapped to a unique PID.
Here’s an example of processes running on a Docker host with two running containers (host PIDs are in pink and container PIDs are in green):
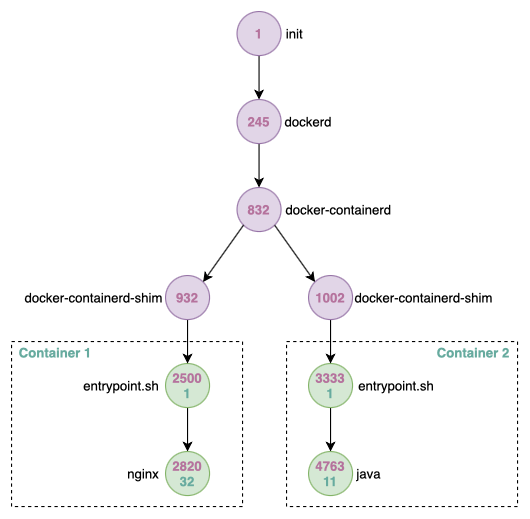
Don’t worry about what these processes do for now, we’ll get to that later.
Notice that from container 1’s perspective, the only running processes are entrypoint.sh and nginx. These processes are assigned PID 1 and PID 32, respectively. Because their parent processes are running in the host system’s PID namespace, the host sees these processes as PID 2500 and PID 2820, respectively.
PID namespaces allow for other interesting container functionality as well, such as migrating our container to a new host without modifying the PIDs of the processes running inside. This will come in handy in a later blog post when we talk about container orchestration.
NET namespaces
Network (NET) namespaces are logical copies of the network stack.
Docker uses NET namespaces for network isolation4. Each container can have its own IP address, gateway, routing table, DNS services, etc.
Mount namespaces
Mount namespaces provide mount point isolation5.
In Docker, container images are mounted to the Linux filesystem as storage devices, and each container’s root directory (/) is mapped to its image’s mount point.
With mount namespaces, processes (or containers) running in each mount point namespace see a distinct single-directory hierarchy from that mount point. In other words, mount namespaces allow a container to see its own distinct Linux filesystem. You can think of them as filesystems within a filesystem.
IPC namespaces
Inter-Process Communication (IPC) namespaces provide isolation for System V IPC objects and POSIX message queues6.
With IPC namespaces, IPC objects are only visible to processes in the same namespace. This prevents containers from seeing or interacting with processes running on the host or in other containers (unless explicitly set).
cgroup namespaces
Control Group (cgroup) namespaces provide isolation for the resource limits imposed on a set of processes.
cgroups are a Linux kernel feature to limit and monitor various types of resources such as memory, CPU, and network bandwidth that a set of processes can consume7. With cgroup namespaces, the resource consumption of each container can be managed, limited, and monitored in isolation from other containers on the host system8.
Docker
Now that we have a rough idea of what containers are and how they use built-in features of the Linux kernel to encapsulate and manage processes, let’s shift our focus to the Docker platform itself.
The Docker platform simplifies container technology by providing two main userland programs for us to work with - the Docker engine and the Docker CLI.
Docker engine
The Docker engine is a stack of components responsible for creating and running containers; its main components are the Docker daemon, runc, and containerd.
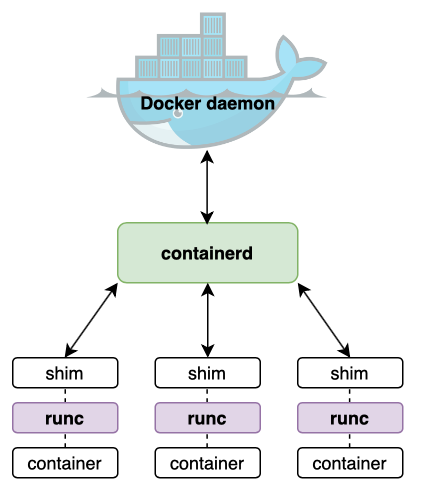
Docker daemon
The Docker daemon runs a server that exposes a public-facing REST API to which clients can connect and use to manage containers9.
runc
runConfig (runc) is essentially a lightweight CLI tool that creates containers from Linux kernel features like namespaces and cgroups10. It also provides support for Linux security features like AppArmor, SELinux, and seccomp.
Every container is initially the child of a new runc process.
containerd
containerd adds higher-level functionality to runc like managing container lifecycle operations, pulling images, mounting volumes, and creating network interfaces11.
containerd is what delegates a new instance of runc to create each new container. Once a container is started, containerd terminates its runc process and delegates a new shim process to manage the container’s lifecycle operations12.
Together, runc and containerd form what is collectively referred to as the container runtime - the low-level functionality responsible for creating and running containers.
Docker CLI
Docker implements a client-server model in which the server is implemented by the Docker daemon and the client is implemented by the Docker CLI. The server running on the Docker daemon exposes a REST API called the Docker Engine API13.
By default, every command we enter into the Docker CLI is converted into an HTTP request payload and sent to the appropriate endpoint on the Docker daemon over a local IPC socket14.
-
Containers share the underlying Linux kernel of the host system. OS-level virtualization requires significantly less overhead than full virtualization based on a hypervisor. ↩
-
Linux facilitates user namespaces by creating mapping tables between user/group IDs inside and outside of a user namespace. ↩
-
PID 1or the “init” process is especially important because it is the first process started at boot time, making it responsible for spawning all other processes (either directly or indirectly). In Docker,PID 1is a container’s primary process from which its running status is derived. ↩ -
Network isolation helps avoid privileged access to the sockets or interfaces of another container. ↩
-
Mount points define the locations of storage devices in the Linux filesystem, the access properties of the data at those locations, and the source of the data. ↩
-
System V IPC refers to interprocess communication mechanisms available on UNIX systems, namely, message queues, semaphores, and shared memory. Message queues allow the prioritized exchange of data between processes using queue structures; POSIX message queues are a functionally similar alternative to System V message queues. Semaphores allow processes to synchronize their actions, and shared memory allows processes to communicate information by sharing a region of memory. ↩
-
The term “cgroup” itself refers to a set of processes that are bound by the same limits. ↩
-
cgroup namespaces help prevent the classical noisy-neighbour problem in cloud environments, where one set of processes can consume all shared resources - effectively resulting in a Denial-of-Service (DoS) attack on other running processes. ↩
-
The Docker daemon started out as one big monolithic application that provided all of the functionality necessary to create and run containers. Over time, as the platform grew in popularity, Docker, Inc. decided to break the Docker daemon down into smaller components. Some components were donated to the open source community in order to promote the wide adoption of Docker’s underlying technologies. Today, the Docker daemon no longer handles any of the functionality related to the explicit creation or execution of containers. ↩
-
runc is based on libcontainer, a native Go implementation for interfacing with Linux kernel features like namespaces and cgroups. It is also the reference implementation of the Open Container Initiative runtime specification (OCI runtime-spec), creating containers according to OCI specifications. Having been donated to open source under the Moby Project, runc can be used by third party tools aside from just Docker and can even be used standalone. ↩
-
Alternative OCI-based container runtime implementations include rkt by CoreOS, CRI-O by Red Hat, and LXD by Linux Containers. ↩
-
The shim process serves an important role in freeing up resources and decoupling the container runtime from the Docker daemon. ↩
-
That’s because, by default, the Docker server is installed on the same host as the Docker client. They can, however, be installed on different hosts with communications using TCP instead. Network communication between client and server can then be secured by TLS. ↩