Git - How it Works
Git is a Distributed Version Control System (DVCS) created by Linux kernel creator Linus Torvalds.
Let’s dive deep into the internals of Git so that we can understand how it works.
It is expected that you have at least a basic general understanding of Git before reading this so that we can keep things as short and concise as possible. I know most of you are already well-versed in Git, but for those who are not, here’s a short introduction written by GitHub. Read that first and then come back, it should be fairly quick.
Let’s start by initializing a new repo in a directory called test:
$ git init test
Now let’s navigate inside of our new test directory and see what’s going on:
$ cd test
$ ls -a
. .. .git
Notice that Git created its own subdirectory called .git.
Let’s peek inside the .git subdirectory:
$ ls -a .git
. HEAD description info refs
.. config hooks objects
You’ll notice it contains a few files, namely, HEAD, config, and description.
The HEAD file points to the branch you’ve currently checked out, the config file contains your project’s configuration options, and the description file is used by a program called GitWeb that provides a web frontend to Git repositories. There is also another file called index that hasn’t been created yet; it’s where your staging area information is stored.
You’ll also notice a few subdirectories, namely, hooks, info, objects, and refs.
The hooks directory contains your hook scripts, the info directory contains an exclude file that keeps a global list of patterns you want Git to ignore, and the refs directory stores your branches.
The objects directory is at the core of our repo; it stores all of our content in a simple key-value data store.
Git has four main object types: blobs, trees, commits, and tags.
Blobs
Let’s create our first object - a binary object we call a blob (Binary Large OBject).
Before we start, let’s make sure our objects directory is empty:
$ find .git/objects -type f
If no files were found, great, that’s what we want; otherwise, make sure you start with a fresh repo so you can follow along.
Let’s now create a file called guestlist.txt with some content and manually store it in our object database:
$ echo 'bob' > guestlist.txt
$ git hash-object -w guestlist.txt
696fb6baa5ce30099c89066294e5973ee42a1899
The command git-hash-object is a plumbing command that takes an object and computes its SHA-1 hash1. The -w option actually writes that object into our object database.
You’ll notice the output of the command is the 40-character hash (including header) 696fb6baa5ce30099c89066294e5973ee42a1899.
Note that Git does not care about the name of the file when creating its hash - it only looks at its content. So if instead of
guestlist.txtwe usedblacklist.txt, our hash would have been the exact same. Try it for yourself without the-woption!
If we now inspect our objects directory again, we should see it stored:
$ find .git/objects -type f
.git/objects/69/6fb6baa5ce30099c89066294e5973ee42a1899
Notice that Git has created a new subdirectory using the first two characters of our hash, 69, and then created a file inside of that subdirectory with filename set to the last 38 characters of our hash, 6fb6baa5ce30099c89066294e5973ee42a1899. In essence what Git has done is stored our object as a key-value pair in its database; the key being the SHA-1 hash and the object being the newly created blob.
We can verify that this object is indeed a blob by running the following command:
$ git cat-file -t 696fb6baa5ce30099c89066294e5973ee42a1899
blob
To prove it’s been stored properly, we can even try deleting our file and retrieving it from our object database:
$ rm guestlist.txt
$ git cat-file -p 696fb6baa5ce30099c89066294e5973ee42a1899 > guestlist.txt
$ cat guestlist.txt
bob
The command git-cat-file is used for inspecting Git objects and the -p option denotes pretty-print.
Trees
Tree objects are Git’s way of storing the directory state of our index (i.e. staging area).
To make this more interesting, let’s add a few more things to our working directory:
$ echo 'this is new' > README.md
$ mkdir lists
$ mv guestlist.txt lists/.
So we’ve created a new file called README.md in the top-level directory. We then created a subdirectory called lists and added our guestlist.txt file to it.
We’re now going to record the state of our index using tree objects.
If this all works as expected, we should end up with two trees and two blobs. The first tree will represent the top-level directory of the index, and it will contain the blob of our README.md file and another tree for our lists subdirectory. The lists tree should then contain the blob of our guestlist.txt file.
To start, let’s add everything to our index; we’ll be using plumbing commands to break this down into steps:
$ git update-index --add README.md lists/*
$ git write-tree
a9f2af46d3db09b6889a03313c5b89f5500aae3d
The command git-update-index adds files to the index. The --add option is there because our files are completely new (new files are ignored by default). The command git-write-tree then creates a tree using the current state of our index.
Notice that Git outputted our newly-created tree’s SHA-1 hash - a9f2af46d3db09b6889a03313c5b89f5500aae3d.
Just for sanity’s sake, let’s make sure it’s indeed a tree object:
$ git cat-file -t a9f2af46d3db09b6889a03313c5b89f5500aae3d
tree
Good, we’re not insane! Now let’s inspect it:
$ git cat-file -p a9f2af46d3db09b6889a03313c5b89f5500aae3d
100644 blob fff92cfdca952aad393fe93d1fc52995bac0b276 README.md
040000 tree fa367486f17fbd97cb9922f56cebe5d3df8768a8 lists
So as expected, our top-level tree has two entries - a blob of our README.md file and another tree for our lists subdirectory. The value 100644 to the left of the blob tells us this is a “normal” file2. The value 040000 to the left of the tree tells us this is a directory.
Let’s now inspect the new lists tree:
$ git cat-file -p fa367486f17fbd97cb9922f56cebe5d3df8768a8
100644 blob 696fb6baa5ce30099c89066294e5973ee42a1899 guestlist.txt
The lists tree has an entry for our guestlist.txt blob, just as expected!
Here’s a visual representation of our object database:
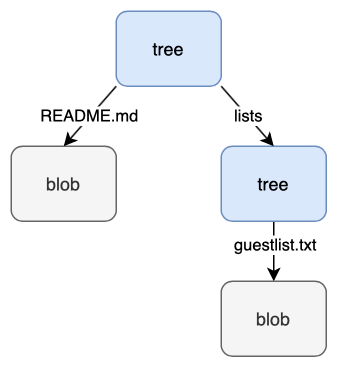
As you can see, all the content in our object database is stored as either trees or blobs.
Commits
Commit objects attach information like author, date, and a message to tree objects. In other words, they help us keep track of changes to our index over time.
Let’s create a commit object for our top-level tree:
$ echo 'Initial commit' | git commit-tree a9f2af46d3
5eac38ace7561353430551bf9daff2bd26fd8bac
The command git-commit-tree creates a new commit object based on the provided tree object. It normally takes the tree’s SHA-1 hash and the previous/parent commit’s hash as parameters. Because this is an initial (root) commit, there are no parents.
Notice we piped in a commit message - Initial commit.
You may also have noticed we ommitted most of our tree’s SHA-1 hash. Git is smart enough to know that we don’t always need all 40 characters to uniquely identify an object3.
In response, Git outputs a SHA-1 hash associated with our new object.
Note that your hash will differ due to your different author/date data
Let’s now inspect our new commit object (be sure to replace the hash below accordingly):
$ git cat-file -p 5eac38ace7
tree a9f2af46d3db09b6889a03313c5b89f5500aae3d
author Reza Nejatali <reza.n@me.com> 1615054555 -0800
committer Reza Nejatali <reza.n@me.com> 1615054555 -0800
Initial commit
The commit object has stored our top-level tree, the author/committer and timestamp data, and our commit message. If we had a parent commit, it would have been stored here as well.
Now let’s try adding a commit with a parent.
We’ll start by making a change to our working directory and adding it to our index. We’ll then record the state of the index into a new tree object. Finally, we’ll use that new tree object to create a new commit.
Add the name mike to our guestlist.txt file:
$ echo 'mike' >> lists/guestlist.txt
Update the index:
$ git update-index --add lists/guestlist.txt
Write the state of the index into a new tree object:
$ git write-tree
d396af9f9f0bb49ea2dab86327744dc24d18dc33
Now create a new commit object:
$ echo 'Add mike to guestlist' | git commit-tree d396af9f9f -p 5eac38ace7
c45b5aa23956fedbb75337b9039e2c7d0125a16f
Notice we included a parent commit this time - the hash of our previous commit.
Inspecting the new commit object looks like this:
$ git cat-file -p c45b5aa239
tree d396af9f9f0bb49ea2dab86327744dc24d18dc33
parent 5eac38ace7561353430551bf9daff2bd26fd8bac
author Reza Nejatali <reza.n@me.com> 1615133151 -0800
committer Reza Nejatali <reza.n@me.com> 1615133151 -0800
Add mike to guestlist
Let’s take a look at our log:
$ git log --stat --oneline c45b5aa239
c45b5aa (HEAD -> master, tag: v2) Add mike to guestlist
lists/guestlist.txt | 1 +
1 file changed, 1 insertion(+)
5eac38a (tag: v1, test) Initial commit
README.md | 1 +
lists/guestlist.txt | 1 +
2 files changed, 2 insertions(+)
The git-log command shows us a history of commits. By default it shows all commits in the current branch, but since our current branch does not point to any of our commits, we specify our last commit object instead.
The --stat option instructs Git to show us a diffstat of our changes while the --oneline option instructs Git to make the output as compact as possible4.
To summarize, we’ve created blobs of our files and added them into our index, we’ve created trees to record snapshots of our index, and we’ve created commits to track these snapshots over time.
Let’s inspect our objects directory again, we should see all of the objects I just mentioned:
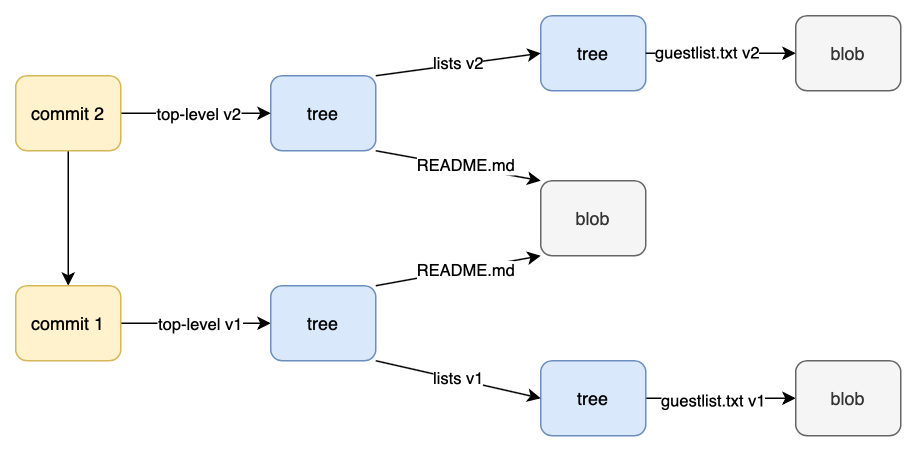
$ find .git/objects -type f
.git/objects/69/6fb6baa5ce30099c89066294e5973ee42a1899 # blob (guestlist.txt v1)
.git/objects/b5/b00bf46743b0240efec87fcb99440c138e8902 # tree (lists v2)
.git/objects/d7/f503f4b3269f2216d46effd684d18d7966026f # blob (guestlist.txt v2)
.git/objects/5e/ac38ace7561353430551bf9daff2bd26fd8bac # commit 1
.git/objects/d3/96af9f9f0bb49ea2dab86327744dc24d18dc33 # tree (top-level v2)
.git/objects/a9/f2af46d3db09b6889a03313c5b89f5500aae3d # tree (top-level v1)
.git/objects/c4/5b5aa23956fedbb75337b9039e2c7d0125a16f # commit 2
.git/objects/fa/367486f17fbd97cb9922f56cebe5d3df8768a8 # tree (lists v1)
.git/objects/ff/f92cfdca952aad393fe93d1fc52995bac0b276 # blob (README.md)
The objects directory contains all of the blob, tree, and commit objects we expected. Together they track all of our content thus far.
Here’s an updated visual representation of our object database:
Tags
Tag objects are similar to commits, but instead of pointing to a tree object, they generally point to a commit object so they can give the commit a user-friendly name.
There are two types of tags in Git - annotated and lightweight.
Lightweight tags are used for private or temporary object labels while annotated tags are typically used to label a commit for release.
Annotated
We can use the following command to create an annotated tag object:
$ git tag -a v2 c45b5aa239 -m "V2 release"
The git-tag command creates, lists, deletes or verifies a tag object signed with GPG5. The -a option creates an unsigned, annotated tag object.
We give our tag the name v2 and specify the SHA-1 hash of the commit object we want to point to.
The -m option allows us to specify a tag message.
Notice that Git did not output the SHA-1 hash associated with our object this time. To find it, we peek inside a newly-generated file named with our tag name in the .git/refs/tags directory:
$ cat .git/refs/tags/v2
2e35090c4ed9aa98ac2afc38adb2df2a1be17f3a
Let’s now inspect it:
$ git cat-file -p 2e35090c4e
object c45b5aa23956fedbb75337b9039e2c7d0125a16f
type commit
tag v2
tagger Reza Nejatali <reza.n@me.com> 1615221886 -0800
V2 release
So our annotated tag object contains the hash of the commit object we are pointing to, the tag name, the tagger’s name/email and timestamp data, and a message6.
Lightweight
To create a lightweight tag, we use the same git-tag command, but without the -a or -m options:
$ git tag v1 5eac38ace7
Just as before, we can find the SHA-1 hash of our tag inside the .gif/refs/tags directory:
$ cat .git/refs/tags/v1
5eac38ace7561353430551bf9daff2bd26fd8bac
Interesting! The hash is the same hash as the commit we are pointing to. That’s because unlike annotated tags, lightweight tags are not objects - they simply assign a name to a commit object.
References
References are a more generic way to describe user-friendly names that point to commit objects. Conceptually, the tags we described in the previous section were just references that stayed constant.
Creating a reference is just a matter of storing the SHA-1 hash of a commit object inside of a file named with the name of the reference inside the .git/refs directory.
Let’s take a harder look at the .git/refs directory:
$ ls -a .git/refs
. .. heads tags
Notice the two subdirectories heads and tags. We’re already familiar with the tags subdirectory because it contains references to the tags v1 and v2 we created in the previous section.
The heads subdirectory contains references to the latest commit in a line of work. Another name for this kind of reference is a branch.
Let’s create a master branch.
The simplest way to do this would be to create a file named master containing the hash of our commit in the .git/refs/heads directory7:
$ echo 'c45b5aa23956fedbb75337b9039e2c7d0125a16f' > .git/refs/heads/master
We can now conveniently use the master reference anytime we want to refer to this commit. For example, using the git-log command:
$ git log --oneline master
c45b5aa (HEAD -> master, tag: v2) Add mike to guestlist
5eac38a (tag: v1, test) Initial commit
As opposed to using the SHA-1 hash of the commit directly, which does the same thing:
$ git log --oneline c45b5aa239
c45b5aa (HEAD -> master, tag: v2) Add mike to guestlist
5eac38a (tag: v1, test) Initial commit
Let’s also create a branch called test and have it point to our first commit:
$ echo '5eac38ace7561353430551bf9daff2bd26fd8bac' > .git/refs/heads/test
Verify that test points to our first commit:
$ git log --oneline test
5eac38a (tag: v1, test) Initial commit
Awesome! So we’ve just created two branches using references - master and test.
Visually, this is what that looks like:
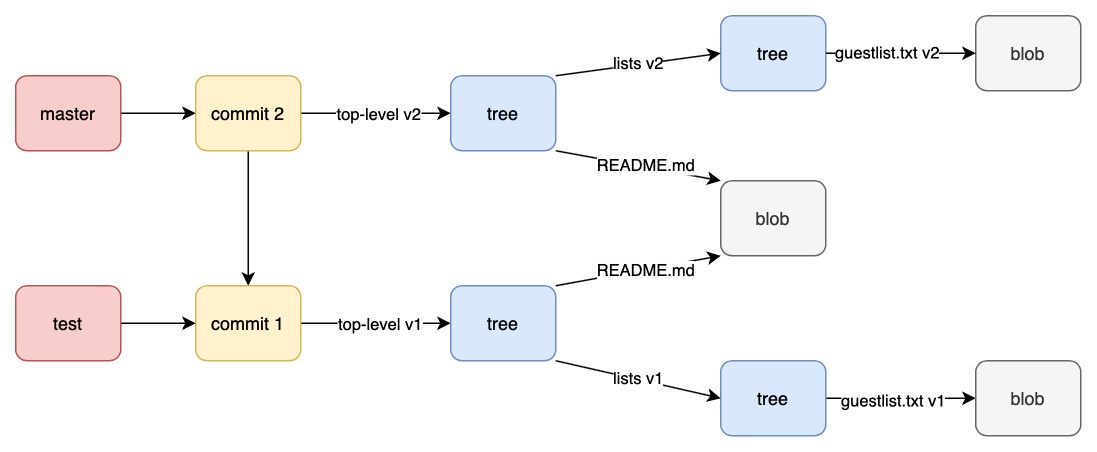
Now, everytime we make a commit, Git updates the SHA-1 hash of our branch to point to the latest commit.
Let’s see this in action. Add the name john to our guestlist.txt file:
$ echo 'john' >> lists/guestlist.txt
Make a new commit:
$ git commit -am 'Add john to guestlist'
[master 3b1d022] Add john to guestlist
1 file changed, 1 insertion(+)
You’re probably already familiar with the command git-commit - it’s the porcelain way to create a new commit object. The option -am instructs Git to automatically stage files that have been modified and to use the given message as the commit message.
Notice that we did not need to specify a parent commit this time. That’s because Git automatically resolves the latest commit from the reference pointed to by the
HEADfile:$ cat .git/HEAD ref: refs/heads/master
In response, Git outputted the first several characters of our new commit’s hash - 3b1d022. We expect the master branch to now contain the same hash.
To check, let’s peek inside .git/refs/heads/master:
$ cat .git/refs/heads/master
3b1d022eb88c6b691c0d0170564a9db0f8601743
Affirmative - the master branch contains the same hash, meaning Git has automatically updated it to point to the latest commit.
-
The original Git developers made a distinction between “plumbing” commands and “porcelain” commands. High-level commands like
git-add,git-checkout,git-merge, etc. are called porcelain commands while low-level commands are called plumbing commands. There is no clearly defined boundary between the two types and [as far as I can tell] the analogy is that of a toilet - most of the time we only really care about the porcelain part that we sit on when we do our business, but once in a while we may need to take a look at the plumbing situation underneath. ↩ -
You may notice these values are analogous to UNIX file descriptors and octal permissions, but as far as Git blobs go, the only possible values are
100644(normal),100755(executable), and120000(symbolic link). ↩ -
In general, the more objects we have, the more hash characters we need to uniquely identify an object. As an example, the Linux kernel project (with its millions of objects) requires at least twelve hash characters to uniquely identify an object. But for most projects, ten characters is more than enough. ↩
-
A diffstat is a histogram of insertions, deletions, and modifications on a per-file basis. ↩
-
GPG or GNU Privacy Guard is the open-source variant of PGP (see my post on asymmetric-cryptography for details). ↩
-
Although we pointed our annotated tag to a commit object, it can technically be pointed to any object in Git. ↩
-
A safer alternative to this command is
git-update-ref. ↩